Today, together with Michele Coscia, we published a paper on Royal Society: Interface, with the title “Distorsions of Political Bias in Crowdsourced Misinformation Flagging” (originally the paper had a much better title, but reviewer 2 called it a “pointless tongue-twister” and you know how these things are…).
The paper analyses the assumptions behind online content-moderation when it is based on users flagging the content they consider to be inappropriate. We show, using agent based modelling, how those assumptions are wrong (thus the strategy is doomed to fail) when users are expected to flag “fake news”.
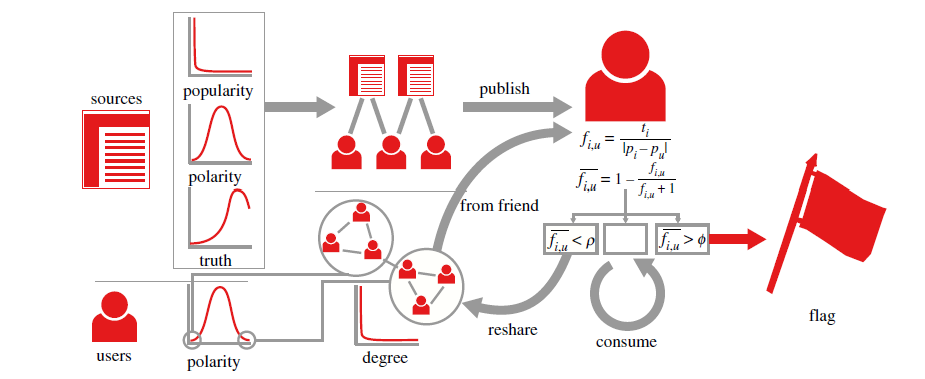
The article is pretty nice, it has a lot of pictures and it’s open access, so you should check it out.
The article also comes with an interesting background story that is probably worth sharing as it contains a lesson we should always keep in mind: reasonable is not enough.
As part of the project “Patterns of Facebook Interactions around Insular and Cross-Partisan Media Sources in the Run-up to Italian Elections” (https://sites.google.com/uniurb.it/mine/home) I had access to the data from the ulr-shares datasets that contains almost all the links that have been shared on facebook. In addition to the links the datasets also contains additional data about how the link performed on the platform as well as if the urls had been shared with third party fact checkers. This is part of Facebook’s effort to fight fake news and it basically works in the following way: when users read something on the platform that they think might be fake they can report the content (they flag it). Then facebook’s algorithms try to remove what they think might be random flags and, when a specific news receives enough flags it is submitted to external fact checkers that will investigate the content.
Digging into the list of what had been sent to external fact-checking we couldn’t avoid noticing that mainstream well established newspapers were largely dominating that list. And that is not the kind of sources one would expect to find there. I discussed this with Michele and we came to the conclusion that this was, after all, an unavoidable consequence of the wrong assumptions made by facebook when they tried to model users as “fake-news detectors”. Facebook approach, we thought, makes sense only if we don’t take into account all the social dynamics that we know exist and play a role in shaping online human behavior: more precisely if we ignore users’ political polarization and homophily.
To test our intuition we build two Agent based models: one that works according to the ideal world that facebook approach seems to assume (that we called monopolar ) and one that account for political polarization and homophily in how the users are connected (that we called bipolar).
The results support our intuition since the the data produced using the bipolar model fits remarkably well the real data of how news-items are flagged on facebook: large, moderate mainstream news outlets are flagged much more than extreme venues (that are almost not flagged).
The explanation behind this is pretty simple, in a polarize and homophilic social network a user will be more tolerant for sources that are politically aligned and less tolerant with sources that belong to a different political sphere. At the same time, circulation of information is highly affected by the homophily that defines the network structure, thus users belonging to one side of the political spectrum will be rarely exposed to content highly aligned with the opposite side. An unintended consequence of this is that moderate sources with large audiences will be the among the few who are actually able to reach both ends of the network and, as soon as the level of tolerance for different opinions goes down, they will get all the flags.
Obviously this work as all the limits of ABMs and there are many additional dynamics we should incorporate (we are already working on a follow-up). Nevertheless, it work as an important reminder: we should never rush to implement a technical solution to a societal problem, ’cause in many cases reasonable and wrong can easily co-exist.